

What just occurred? Microsoft has launched BitNet b1.58 2B4T, a novel type of large language model designed for remarkable efficiency. In contrast to traditional AI models that utilize 16- or 32-bit floating-point numbers for weight representation, BitNet employs just three discrete values: -1, 0, or +1. This methodology, termed ternary quantization, allows for each weight to be stored using only 1.58 bits, significantly minimizing memory usage. Consequently, the model can operate much more efficiently on standard hardware without the necessity for high-performance GPUs typically required by large-scale AI systems.
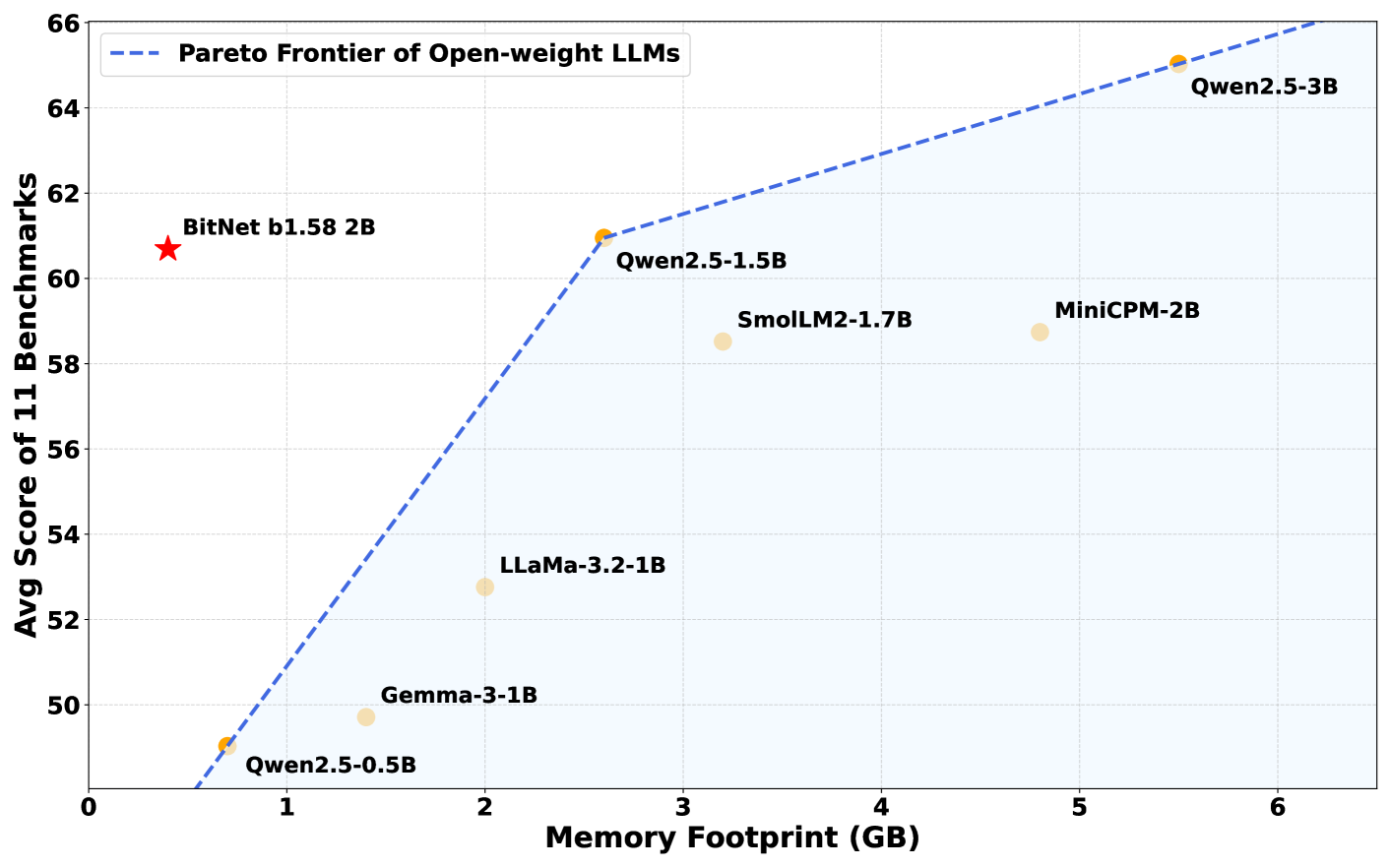
The BitNet b1.58 2B4T model was created by Microsoft’s General Artificial Intelligence group and comprises two billion parameters, which are internal values that facilitate the model’s understanding and generation of language. To make up for its low-precision weights, the model was trained on an extensive dataset of four trillion tokens, roughly equivalent to 33 million books in content. This extensive training enables BitNet to perform equivalently to—or in certain scenarios, even surpass—other prominent models of comparable size, such as Meta’s Llama 3.2 1B, Google’s Gemma 3 1B, and Alibaba’s Qwen 2.5 1.5B.
In benchmark assessments, BitNet b1.58 2B4T exhibited outstanding performance across various tasks, including elementary math problems and inquiries demanding common-sense reasoning. In some evaluations, it even outperformed rival models.
What truly distinguishes BitNet is its memory efficiency. The model requires only 400MB of memory, less than one-third of what comparable models typically necessitate. As a result, it can function smoothly on standard CPUs, including Apple’s M2 chip, without the need for high-end GPUs or specialized AI hardware.
This impressive level of efficiency is facilitated by a custom software framework called bitnet.cpp, which is optimized to fully leverage the model’s ternary weights. The framework guarantees fast and lightweight performance on everyday computing devices.
Standard AI libraries like Hugging Face’s Transformers do not provide the same performance benefits as BitNet b1.58 2B4T, emphasizing the necessity of the custom bitnet.cpp framework. Available on GitHub, the framework is currently tailored for CPUs, with plans to support additional processor types in future updates.
The concept of reducing model precision for memory conservation isn’t novel. Researchers have long investigated model compression. However, many previous efforts focused on converting full-precision models post-training, often compromising accuracy. BitNet b1.58 2B4T adopts a different tactic: it is trained from scratch using only three weight values (-1, 0, and +1). This strategy helps avert many performance compromises seen in earlier techniques.
This transition carries substantial implications. Running large AI models usually requires powerful hardware and significant energy resources, factors that escalate costs and environmental impacts. Because BitNet relies on extremely simple computations—primarily additions rather than multiplications—it consumes far less energy.
Microsoft researchers estimate that it uses 85 to 96 percent less energy than comparable full-precision models. This advancement could enable running sophisticated AI directly on personal devices without relying on cloud-based supercomputers.
However, BitNet b1.58 2B4T does have certain limitations. It currently supports only specific hardware configurations and necessitates the custom bitnet.cpp framework. Additionally, its context window—the volume of text it can process in one go—is smaller compared to leading-edge models.
Researchers continue to explore the reasons behind the model’s impressive performance with such a simplified architecture. Future developments are aimed at expanding its features, including support for a greater variety of languages and processing longer text inputs.

